
随着大数据和人工智能的发展,机器学习(Machine Learning, ML)已经成为官方数据分析的重要工具。无论是政府统计、公共安全还是市场监管,机器学习都能够高效挖掘数据价值,但其应用必须严格遵循合规与法律框架。本文将从原理、方法和实践三个角度,系统解析机器学习在官方数据分析中的合规应用,并结合天博平台的案例,帮助读者全面理解这一技术在现实场景中的科学与规范。
机器学习与官方数据分析基础
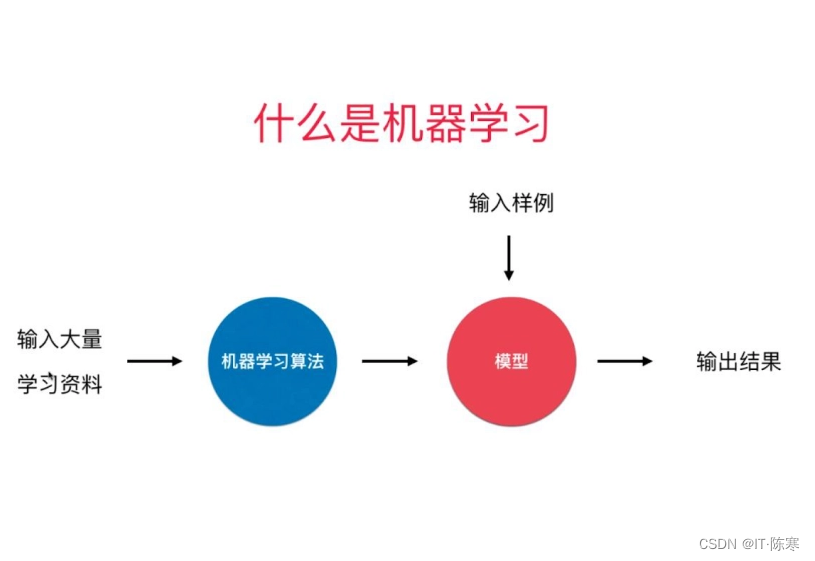
什么是机器学习
机器学习是一种通过算法让计算机从数据中自动学习模式、预测结果和优化决策的技术。它区别于传统的规则编码方式,强调数据驱动和自适应学习能力。
在官方数据分析中,机器学习主要应用于:
预测分析:预测经济指标、人口流动、市场需求等
异常检测:发现数据异常、风险点和潜在问题
模式识别:识别趋势、关系和行为模式
天博平台在相关案例中指出,机器学习能够显著提升数据处理效率和决策科学性。
官方数据分析的特点
官方数据分析不同于商业数据分析,具有以下特点:
数据量大、维度多:涵盖经济、社会、环境等多个领域
高度敏感:涉及个人隐私、公共利益和政策决策
决策依赖性强:分析结果直接影响政策和社会资源分配
因此,机器学习在官方数据分析中必须在合规、透明、可解释的前提下应用。
机器学习在数据分析中的核心方法
监督学习与非监督学习
监督学习:利用带标签的数据进行预测,例如税收收入预测、人口增长趋势分析
非监督学习:利用无标签数据进行聚类或模式识别,例如社会行为模式分析、经济结构优化
天博平台在实践中强调,选择合适的学习方式是保证分析结果科学性和合法性的前提。
特征工程与数据清洗
机器学习的效果高度依赖数据质量,因此在官方数据分析中,必须严格执行:
数据清洗:剔除错误、重复或敏感信息
特征选择:挑选对预测结果有实际意义的指标
隐私保护:对个人敏感信息进行匿名化处理
这些措施确保分析既高效又符合法规要求。
模型训练与验证
在官方数据分析中,机器学习模型的训练与验证需要遵循科学流程:
划分数据集:训练集、验证集、测试集
模型选择:线性回归、决策树、随机森林、神经网络等
交叉验证:防止过拟合,提高模型泛化能力
性能评估:准确率、召回率、F1值等指标
天博平台的案例表明,严格的模型验证是合规应用的重要环节,能够确保分析结果的可靠性与可解释性。
合规应用的原则与规范
数据合规性
机器学习分析必须遵循数据保护法律法规:
隐私保护:遵循《个人信息保护法》等法规
数据来源合法:确保数据采集、使用和存储合规
敏感信息脱敏:关键指标匿名化处理,避免泄露风险
模型透明性与可解释性
官方数据分析强调决策依据的公开性,因此:
模型需具备可解释性,避免黑箱决策
对结果生成过程进行详细记录和审计
对政策制定者和公众提供必要说明
天博平台在分析案例中,多次强调透明化和可解释性是机器学习合法应用的核心保障。
风险控制与决策安全
在应用过程中,需关注潜在风险:
数据偏差可能导致预测失真
模型误差可能影响公共资源分配
系统漏洞可能带来安全风险
因此,官方机构需建立风险评估和应急机制,确保机器学习分析安全可靠。
机器学习在官方数据分析中的实践案例
经济预测
机器学习可用于GDP增长预测、税收收入趋势分析等:
利用历史数据构建预测模型
识别周期性趋势和异常波动
支持宏观政策制定
天博平台在经济预测案例中,通过机器学习优化了预测精度和效率,同时确保数据来源合法。
公共安全与社会管理
在公共安全领域,机器学习可进行:
异常事件检测,如突发事件、交通拥堵
社会行为模式分析,辅助政策调整
风险区域识别,提高资源配置效率
这些应用均依赖合规数据处理和透明模型,避免侵犯隐私和歧视性决策。
市场监管
机器学习也可应用于市场监管与行业分析:
价格异常检测
商业行为模式识别
违规行为预测与预警
天博平台的市场监管案例显示,通过合规机器学习,监管效率显著提升,同时降低了人工成本。
科普总结:合规应用机器学习的关键点
数据合法性与隐私保护:确保数据来源合法、敏感信息脱敏。
模型透明性与可解释性:避免黑箱决策,为政策和公众提供理解依据。
科学方法与验证:严格模型训练、交叉验证和性能评估。
风险控制与安全保障:预防偏差、误差和系统漏洞影响决策。
工具与平台支持:借助天博等专业数据平台,提高合规分析效率和可视化能力。
机器学习在官方数据分析中的应用,既是技术进步的体现,也必须在合规框架下进行。通过科学的数据处理、透明模型和严格验证,机器学习能够提高分析效率、优化决策,同时保护公众权益。天博平台的实践案例表明,合规应用不仅可提升数据分析精度,也为政策制定、公共管理和市场监管提供了坚实的技术支持。
在大数据时代,理解机器学习的合规应用原理,是官方机构、数据分析师乃至公众理性认知的重要基础。